要点(30秒で): DeepSeekが投機的デコーディング手法「DSpark」と訓練基盤「DeepSpec」をMITライセンスでOSS公開した。V4 Flashで1ユーザーあたりの生成速度が60〜85%向上し、自前モデル用の高速ドラフトモデルを訓練するレシピもそのまま手に入る。LLM推論コストに悩むチームは、まずDeepSpecのQwen3/Gemma4向けレシピを動かしてみるのが早い。
DeepSeekが、自社V4モデルの生成速度を実プロダクションで大きく押し上げる投機的デコーディング技術「DSpark」の論文と、その全部入り訓練・評価コード「DeepSpec」を同時に公開した。
派手な新モデルではなく、推論側の地味だが重要な層の話だ。だからこそ業界の見方が変わる——これまで「モデルを大きくする/小さくする」しか議論できなかったコスト最適化に、ドラフトモデルを差し替えて殴るという第三の選択肢が、誰でも手に届くオープンソースの形で降ってきた。
背景・文脈
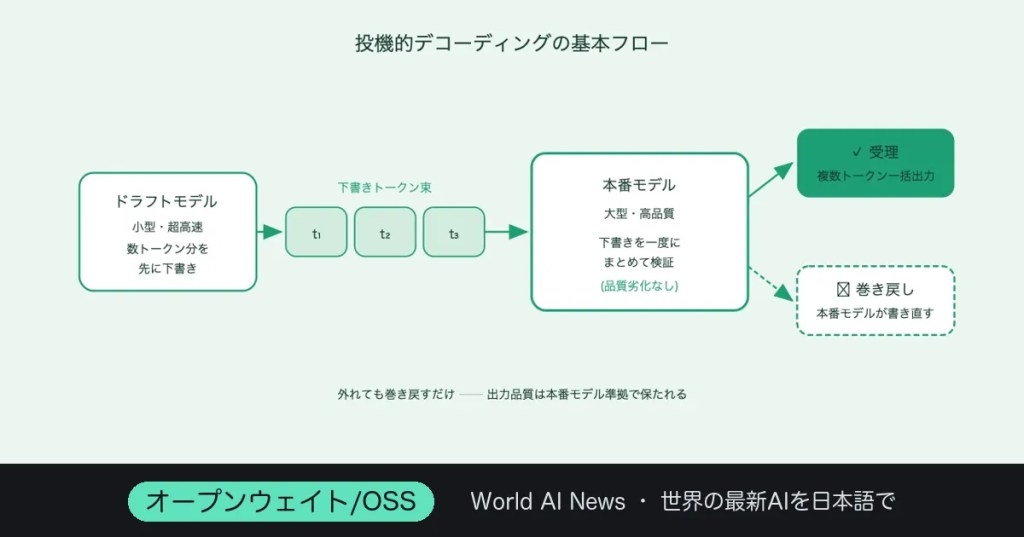
投機的デコーディングは、小さなドラフトモデルで次の数トークンを先に「下書き」し、本番モデルがそれを一度にまとめて検証するという推論高速化の手法だ。受理されれば一気に複数トークンを出せるし、外れたら巻き戻すだけなので、出力品質は劣化しない理屈になっている。
これまで本命と目されてきたのが「Eagle」系(小型の自己回帰ヘッドで逐次生成)と「DFlash」系(複数位置を並列に生成)だ。DeepSeek自身も従来はMTP-1と呼ばれる1トークン先読み方式を本番で使ってきたが、これは構造的に伸びしろが小さく、長文生成の体感速度に天井ができていた。DSparkはそこを正面から潰しに来た位置づけになる。
投機的デコーディングの基本フロー──小さなドラフト→本番モデルが一括検証→品質を保ったまま高速化
仕組み・特徴
DSparkの正式名称は「Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation」。要するに、並列で粗く下書きし、直前1トークンだけ見る軽い順次ヘッドで文脈を補い、信頼度スコアでGPU混雑に応じて検証長を可変にする——という三段構えだ。
順次ヘッドは「直前のトークンだけ参照するMarkovヘッド」で、rank-256の低ランク因子分解にすることで計算コストをほぼ無視できる水準に抑えている。これでDFlash型の弱点だった「並列ゆえに後半トークンの整合が崩れる現象」——論文中でsuffix decayと呼ばれる現象を効かせて消しに行く。
もう一つの肝が信頼度スケジューリングだ。下書きトークン1つ1つに「これは検証で生き残れるか」のスコアが出る。さらにSequential Temperature Scalingというキャリブレーション処理で、推定誤差を3〜8%から約1%まで圧縮する。
その上で、サーバ負荷を見ながら「GPUが空いている時は多めに検証、混んでいる時は少なめに」と長さを自動調整する。個別ユーザのレイテンシを最小化するのではなく、サービス全体のスループットを最適化しに行く設計思想だ。

DSparkの三段構え設計──並列ドラフト×軽量Markov補正×信頼度スケジューリングで「損失なし」のまま速度を稼ぐ
性能・ベンチマーク
オフラインの受理長(accepted length)でみると、Qwen3-4B/8B/14Bの3サイズでEagle3を約27〜31%、DFlashを約16〜18%上回ったとされる。論文中では、層数の少ない2層DSparkが5層DFlashを上回るケースも報告されている——アーキテクチャの設計勝ちだ。
そして実プロダクションのDeepSeek-V4ではMTP-1ベースラインに対し、Flashで60〜85%、Proで57〜78%の1ユーザー高速化を達成。スループット観点では条件次第で51〜400%という幅広い数字が公表されており、特に厳しいSLAではMTP-1が頭打ちになる領域でDSparkの優位が極端に開く。
ベンチマークはGSM8K、MATH500、AIME25、HumanEval、MBPP、LiveCodeBench、MT-Bench、Alpaca、Arena-Hard-v2と、数学・コード・対話を網羅した9種類で評価されている。コーディング系で特に伸びが大きく、エージェント用途の追い風になりそうだ。
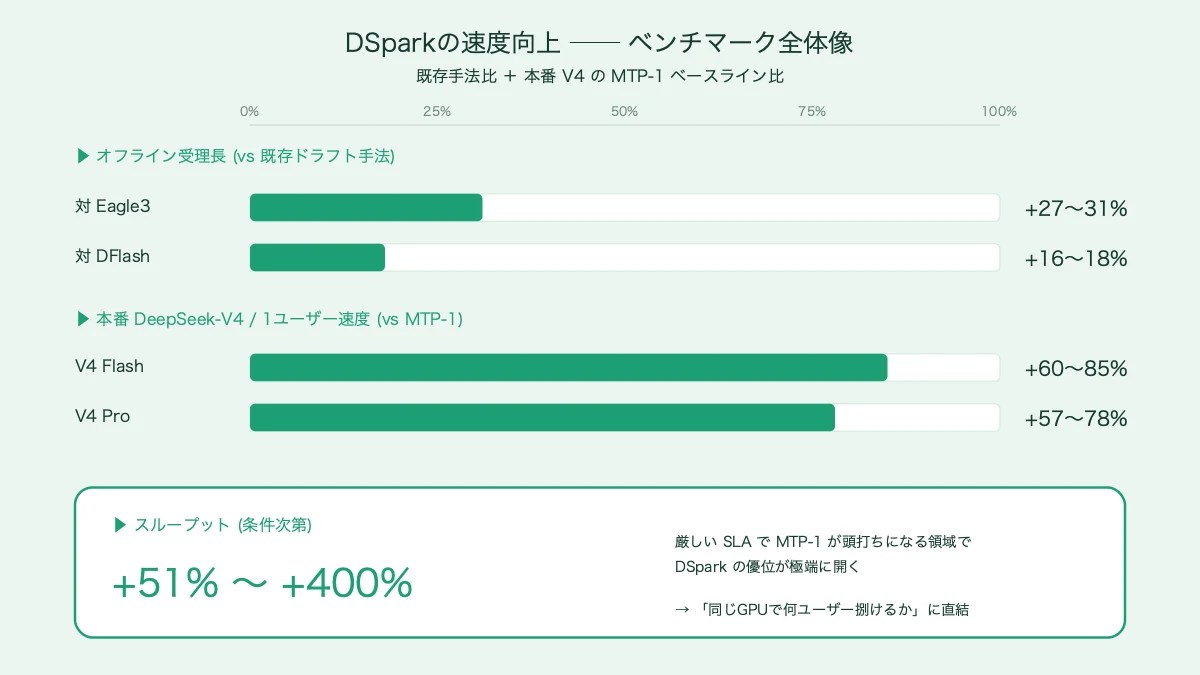
DSparkの速度向上ベンチマーク──既存ドラフト手法比+本番V4のMTP-1ベースライン比、そしてスループット
使いどころ・始め方
DeepSpecの真価は、重みだけではなく訓練コードごと配ったことにある。リポジトリには3アルゴリズム(DSpark/DFlash/Eagle3)の実装、データ前処理、マルチGPU訓練、評価まで一通り入っており、MITライセンスだ。
ターゲットモデルとして公式に動作確認されているのはQwen3(4B/8B/14B)とGemma4-12Bで、DeepSeek-V4本体は重みを差し替えるのではなく既存重みにDSparkモジュールを後付けする設計になっている。これは商用LLMサービスを運用しているチームには大きい——既存資産を捨てずに、ドラフト層だけ差し込んで速くできる。
ハードル感も書いておくと、デフォルト訓練設定で8GPUノード1台+約38TBのターゲットキャッシュ用ストレージが必要だ。個人で家で回すには重いが、クラウド数千ドル規模の話なので、自社モデルを抱えるスタートアップ規模なら現実的に手が届く範囲だろう。
リポジトリは公開数日でスター1.6kを集めており、すでに第三者の評価実験や派生フォークが動き始めている。
日本・個人開発の視点
国内のLLM推論基盤チームにとって、これは「自社モデル+自前ドラフト」という選択肢が初めて現実的に降りてきた瞬間だ。たとえばHaystack 2.30、本番AIエージェント基盤の本命——RAGの先へで取り上げたエージェント基盤や、Rubyで全AIプロバイダを束ねる「RubyLLM 1.16」が来たで見たマルチプロバイダ統合層の下に、DSpark的な高速化レイヤがくっついていく未来は十分にあり得る。
GPU単価がまた値上がりしている今、「同じGPUで何ユーザー捌けるか」が事業の生死を分けるフェーズに入った。DSparkは、その係数を1.5〜1.8倍に動かしてくる類の道具だ。
要点まとめ
- DSparkは並列ドラフト+軽量Markov順次ヘッド+信頼度スケジューリングを組み合わせた、損失なしのLLM推論高速化手法
- DeepSeek-V4 FlashでMTP-1比60〜85%、ProでもMTP-1比57〜78%の1ユーザー高速化を達成
- Eagle3/DFlashに対し、オフラインの受理長で約27〜31%/約16〜18%上回る
- 訓練・評価コード「DeepSpec」がMITライセンスでOSS公開、Qwen3とGemma4-12Bを公式サポート
- 重みを差し替えず後付け可能な設計で、既存LLMサービスの推論コスト最適化に直結する
🐦⬛ 編集部の視点
DSparkが面白いのは、「論文を出して終わり」ではなく論文・本番システムへの組み込み実績・訓練コードを三点セットで放り込んできた点にある。OpenAIやAnthropicの推論最適化はクローズドな箱の中で完結してきたが、DeepSeekは「中身も訓練レシピも全部見せる」スタンスを今回も貫いた。
Anthropic告発、Alibabaが2880万回Claudeを”蒸留”——史上最大の盗用作戦で見たような「閉じた巨人から盗む」構図の対極で、透明性で勝負しに来る中国勢という構図がいよいよ鮮明になってきた。
このニュースを大きく扱う理由は単純で、LLM運用コストの議論の中心が「どのモデルを使うか」から「どう速く回すか」に移ったことを象徴する一発だからだ。読者に問うとすれば——あなたのプロダクトの推論コスト、今のドラフトモデル構成で本当に下限ですか、と聞きたい。




コメントを残す