要点(30秒で): Solanaのウォレットで払ってGPUやAIモデルを借りられる「OpenRAM」が公開された。ただし中身はVast.aiのGPUとOpenRouterのモデルをSOL決済で再販する”取次”で、独自トークン$RAMはまだ未発行。飛びつく前に、何を借りているのか一度きちんと見極めておきたい。
GitHubに「tryOpenRAM/OpenRAM」というリポジトリが現れた。キャッチコピーは「GPUを借りて好きなAIモデルを動かせる、支払いはSOL」。そして「$RAMで買えば割安、使われた$RAMはすべて焼却される」という一文が添えられている。
一見すると、いま盛り上がっている分散GPUネットワークの新顔に見える。だが取材して中身を開けると、印象はだいぶ変わってきた。
何をするサービスなのか
OpenRAMが提供するのは、大きく分けて二つだ。ひとつは「まるごと一台のマシン」を時間貸しで借りる機能。RTX 3060からH100級までのGPUが並び、VRAMやvCPU、リージョン、時間あたりの料金がSOL建てで表示される。
借りたマシンにはSSHでつなげるほか、ブラウザ上のJupyterノートブックも使える。起動は数分。ここは、GPUを丸ごと占有して好きに使いたい人向けだ。
もうひとつが「APIキー」。プリペイド式のキーを一本持てば、Claude・Llama・Qwen・DeepSeekなど139以上のモデルを、OpenAI互換のエンドポイント経由で叩ける。既存のコードのURLと鍵を差し替えるだけで動く、いわゆるドロップイン型だ。

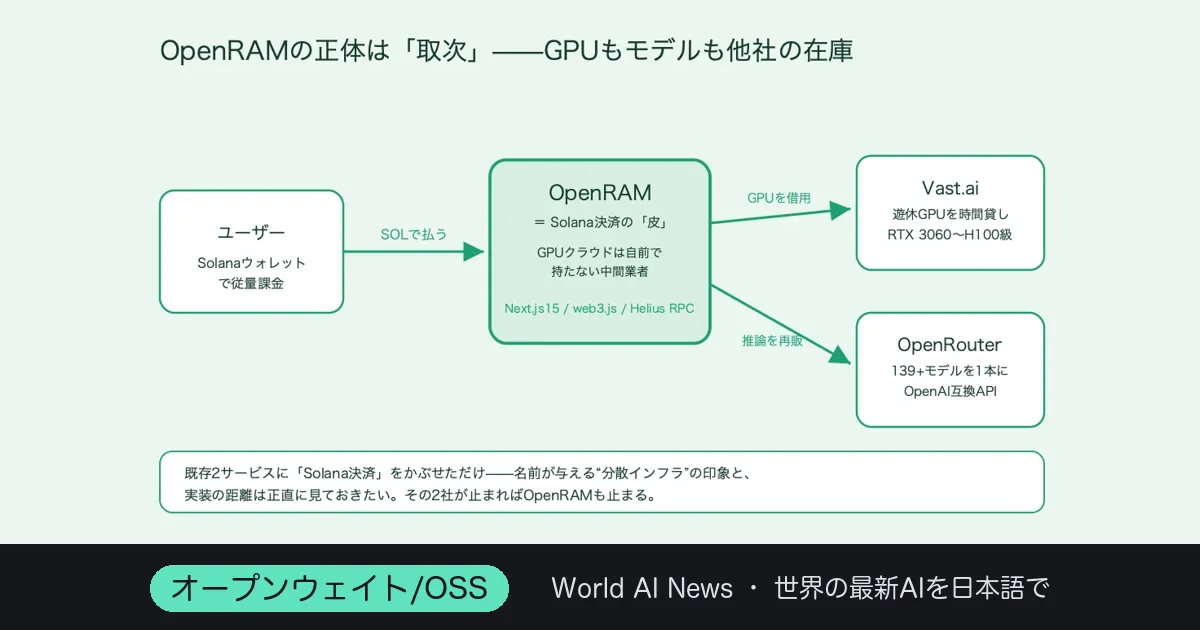
図1:OpenRAMの正体は「取次」。SOL決済の皮の下で、GPUはVast.ai・モデルはOpenRouterを呼んでいる(仕組み図)
中身は”取次”だった
ここが肝心なところだ。OpenRAMのGPUは、実体としてはVast.aiの在庫を借りている。世界中の遊休GPUを時間貸しするあの市場を、裏側でそのまま呼び出している。
モデル推論のほうも同じで、139モデルという数字の出どころはOpenRouter。500以上のモデルを一本のAPIに束ねるルーターを、OpenRAMが再販しているかたちだ。技術スタックはNext.js 15とTypeScript、ウォレット連携にSolanaのweb3.js、決済の検証にはHelius RPCを使っている。
つまりOpenRAMは、GPUクラウドを自前で持っているわけではない。既存の二つのサービスに「Solana決済」という皮をかぶせ、間に立つ取次業なのだ。悪いとは言わない。ただ、名前から受ける”分散インフラ”の印象と、実装の距離は正直に見ておきたい。

図2:$RAMのデフレ設計——半額で需要を作り、焼却で供給を絞る。ただし今は「予告」段階(処理フロー図)
$RAMという仕掛け
このプロジェクトの主役は、むしろトークン経済のほうだ。決済時にSOLか$RAMかを選べて、$RAMで払うと50%割引になる。そして使われた$RAMはトレジャリに集められ、10分ごとに自動で焼かれていく。
供給が使うほど減っていく、いわゆるデフレ設計だ。「プラットフォームが使われるほど$RAMは希少になる」という物語がここに乗る。半額という強い割引でトークンの需要を作り、焼却で供給を絞る——需給の両側を同時に押す、典型的なトークンローンチの型である。
ただし現時点で$RAMはまだ出ていない。サイトの表記は「$RAM launches soon(近日ローンチ)」で、いまはSOLで払えるだけ。焼却も割引も、トークンが実際に走り出してからの話になる。ここは冷静に押さえておくべき点だ。

図3:同じ「分散GPU」でも立ち位置が違う。OpenRAM(取次)と既存DePIN(供給を自前で分散)の比較(比較表)
既存のDePINと何が違うのか
Solana上のAI計算といえば、先行するのはio.netやRender、Akashといった顔ぶれだ。io.netは10万を超える遊休GPUをRayで束ね、AWSより5〜7割安いクラスタを貸す。Akashは逆オークションで価格を競わせ、2026年に入っても稼働率は8割超という。
RenderはもともとEthereum発だが2023年にSolanaへ移り、2025年12月にはAI計算のサブネットを立ち上げた。いずれも「供給側の分散」に本気で投資してきたネットワークだ。
対してOpenRAMは、供給の分散を自前でやっているわけではない。既存の集中型プロバイダを呼び、決済をSOLに寄せ、トークンで人を集める。DePINの見た目をまといつつ、実際にやっているのは決済とトークン設計の再構成に近い。同じ”分散GPU”という言葉でも、立っている場所はかなり違う。
なお名前についても一言。「OpenRAM」はもともと、大学発のよく知られたオープンソースのメモリ(SRAM)コンパイラの名前だ。今回のtryOpenRAMは、その名を借りた別物である点は混同しないほうがいい。
気をつけたい点
コミュニティ市場では、ユーザー自身が自分の計算資源やAPIを出品できる。売上は99%が出品者、1%がトレジャリという配分で、APIはテスト呼び出し、マシンはSSHのプローブで事前検証してから公開される仕組みだ。検証の設計自体はまっとうに見える。
一方で、GPUもモデルも他社の在庫である以上、その二社が止まればサービスも止まる。加えて主役のトークンが未発行で、割引や焼却は”予告”の段階にある。半額という言葉だけで$RAMを先に買い込むのは、素性のわからないトークンにポジションを取る行為に等しい。冷静に距離を取りたいところだ。
日本・個人開発の視点
日本の個人開発者にとって、実利があるのはトークンより「SOLでGPUとAPIを買える」という決済の一点だろう。クレジットカードや法人契約の壁を飛び越え、ウォレットひとつで従量課金に入れる手軽さは確かにある。
ただ、単発の実験なら手元のマシンでローカルLLMを回すほうが速くて安いことも多い。Ollamaのような選択肢が身近にある以上、「わざわざSOLで借りる理由があるか」を毎回問う癖はつけておきたい。
要点まとめ
- OpenRAMはSolanaのウォレットでGPUとAIモデルを借りられるサービス。GPUはVast.ai、モデルはOpenRouterを再販する取次型だ。
- APIキーは139以上のモデルにOpenAI互換で接続でき、既存コードへ差し込みやすい。
- 独自トークン$RAMは50%割引と10分ごとの自動焼却が売りだが、現時点では未発行で「近日ローンチ」の段階。
- io.netやAkashのように供給側を自前で分散しているわけではなく、DePINの見た目とは実装が異なる。
- 名称は大学発のメモリコンパイラ「OpenRAM」とは無関係の別プロジェクト。
🐦⬛ 編集部の視点
このプロジェクトが面白いのは、退屈なほど地味な現実(Vast.aiとOpenRouterの再販)と、派手なミーム経済(半額と焼却)が、一枚のサイトに同居しているところだ。AI計算という重たいインフラの話が、いつのまにかトークンの需給ゲームにすり替わっていく——その継ぎ目がくっきり見える標本になっている。
私たちが注視したいのは、「焼却」という言葉の使われ方だ。供給が減ること自体は、そのトークンで買えるGPU時間の価値を一ミリも増やさない。にもかかわらず、焼却は”価値が上がる物語”として機能してしまう。計算資源の実需と、トークンの希少性演出は、本来まったく別の話なのに。
だからこそ問いたい。あなたがOpenRAMで欲しいのは、H100の1時間なのか、それとも$RAMの含み益なのか。前者なら取次の手数料と安定性を、後者なら未発行トークンのリスクを見る。同じ画面でも、見るべき数字はまるで違う。ここを取り違えないことが、この手のサービスと付き合う最初の一歩になる。
出典・リンク
- 出典: https://github.com/tryOpenRAM/OpenRAM
- OpenRAM 公式サイト: https://tryopenram.app/
- Vast.ai(GPUレンタル市場): https://vast.ai/
- Vast.ai OpenAI互換API ドキュメント: https://docs.vast.ai/guides/serverless/openai-compatible-api
- What Is io.net?(CoinGecko): https://www.coingecko.com/learn/what-is-io-net-io-token
- Decentralized GPU Networks 2026(BlockEden): https://blockeden.xyz/blog/2026/02/07/decentralized-gpu-networks-2026/
- 参考: OpenRRAM(本来のOpenRAM系オープンソース・メモリコンパイラ): https://github.com/akashlevy/OpenRRAM

コメントを残す