要点(30秒で):
– ElevenLabsが6月、ワルシャワの「ElevenSummit」で次世代音声モデル v4 を初披露。囁き・歌・感情・アクセントまで操れる。
– OpenAIの Realtime API は正式版に。GPT-Realtime-2 は会話の割り込みに動じず、道具を並行で使い、電話までかけられる。
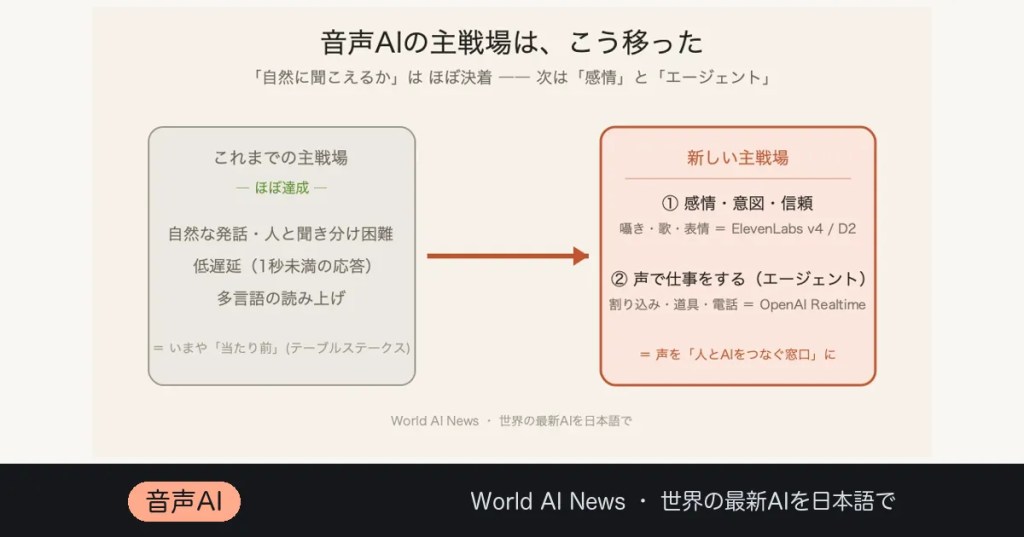
– 音声AIの主戦場は「自然に聞こえるか」から、「感情で信頼を得られるか」「声で仕事をこなせるか」 へ移った。
– 市場規模は約64億ドル、年30%超で成長中。声は“次のインターフェース”になりつつある。
ここ数年、AIの音声合成は「機械っぽさ」との戦いだった。けれど2026年のいま、その戦いはほぼ決着がついている。プロの目で聞いても人間と区別がつかない声は、もう珍しくない。
では次の主戦場はどこか。答えは2つ——感情と、エージェント(声で仕事をするAI)だ。6月に立て続けに飛び込んできた2つのニュースが、その移り変わりをはっきり映し出している。
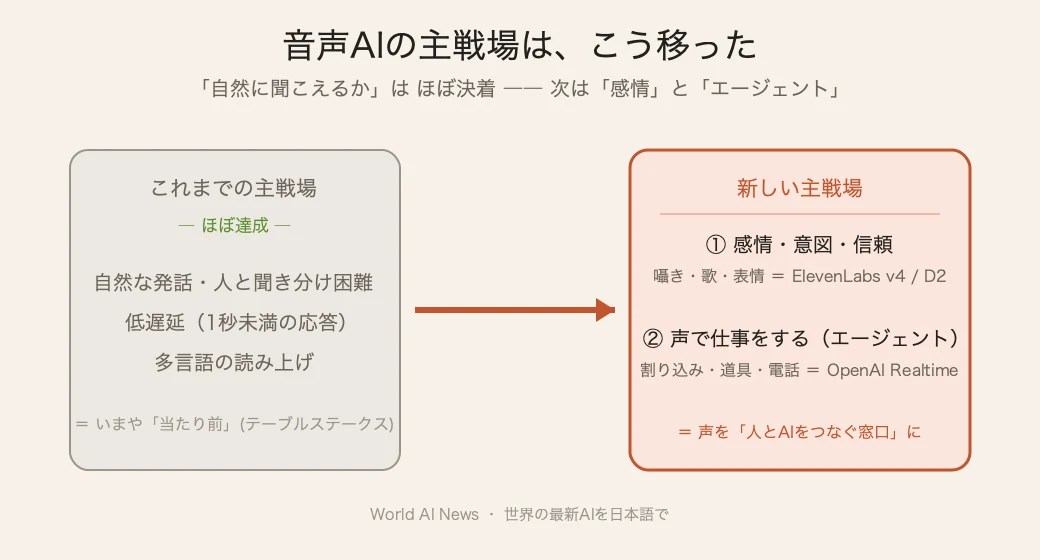
▲ 自然さ・低遅延はほぼ達成済み。次の主戦場は「感情」と「声で仕事をするエージェント」。
ElevenLabsの「v4」——声が感情の領域に踏み込む
音声AIのトップランナー、ElevenLabs(イレブンラボ)が6月、ポーランド・ワルシャワの歴史ある劇場テアトル・ヴィエルキで自社カンファレンス「ElevenSummit」を開いた。そこで初めて披露されたのが、次世代の音声モデル v4 だ。
v4はまだ正式リリース前で、この日は来場者に向けたサンプルのお披露目という位置づけ。だが見せた中身が刺激的だった。囁くような小声、歌、感情の起伏、アクセントの切り替え——これまで「棒読みでない」ことがゴールだった音声AIが、人の声がもつ表情の機微にまで手を伸ばしてきた。
創業者のマティ・スタニシェフスキ氏の言葉が、狙いを端的に表している。
「賢いシステムは作れる。けれど、その声がロボットのように聞こえたら、誰もそのAIを信頼しない」
つまり彼らにとって、声の自然さは“おまけ”ではなく、AIが人に信頼されるための土台なのだ。
サミットではもう一つ、D2という新しい吹き替え(ダビング)システムも公開された。従来のAI吹き替えは、台本のテキストから音声を作るため、どうしても表情が平板になりがちだった。D2は発想を変え、元の音声そのものを聞き取り、話者の感情や演技ごと別の言語へ運ぶ。映画の主役が放った緊張感や笑いを、翻訳先の言語でもそのまま再現しようという試みだ。
ElevenLabsは声を、特定のアプリの機能ではなく「あらゆる接点で使われる共通の対話レイヤー」と位置づける。実際、ドイツテレコムやオンライン教育のMasterClass、ポーランドの公的医療基金(NFZ)、さらにはギリシャ政府の観光案内まで、同社の音声エージェントは日々“何百万件”規模の対話をこなしているという。
OpenAIの「Realtime API」——声がそのまま仕事をする
もう一方の主役が、OpenAIだ。同社の Realtime API(リアルタイムAPI)は、試験的な提供から正式版へと格上げされ、本番運用に耐える“声のエージェント”を作るための土台になった。
中心となる GPT-Realtime-2 が手にした能力は、これまでの音声AIの弱点をそのまま潰しにきている。
- 割り込みに強い:人が話の途中で口を挟んでも、文脈を見失わない。実際の電話のような、かぶせ気味の会話に対応できる。
- 道具を並行で使う:会話しながら複数のツール(在庫照会、予約、検索など)を同時に呼び出せる。
- 記憶が4倍に:一度に保持できる文脈が12万8千トークンへ拡大。長い相談ごとでも話の筋を保てる。
さらに、GPT-Realtime-Translate は70以上の言語をその場で同時通訳し、SIPという仕組みで普通の電話回線にAIが直接出られるようにもなった。声のAIが、画面の中だけでなく、電話の向こう側に座り始めたということだ。
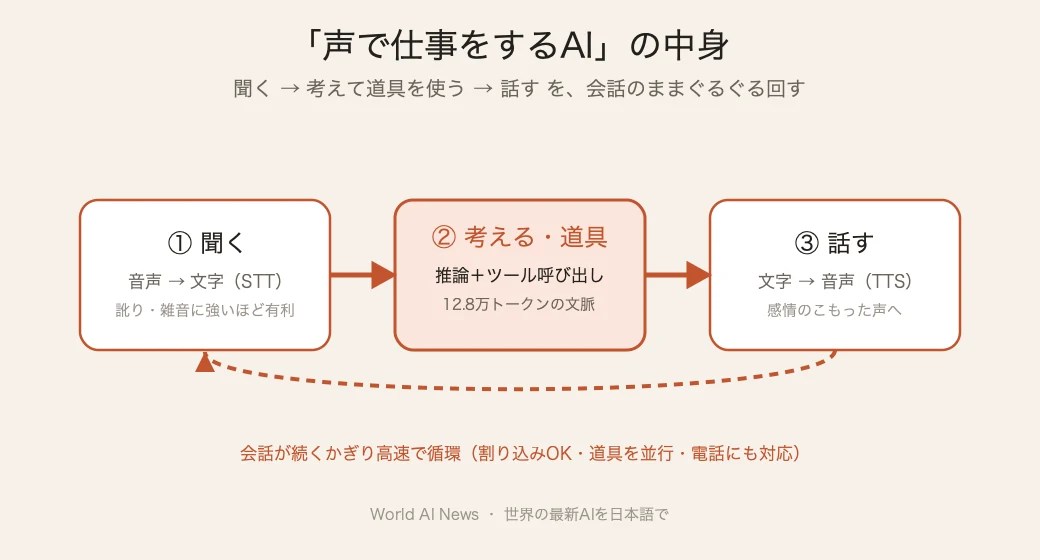
▲ 聞く→考えて道具を使う→話す、を会話のまま高速で循環させるのが音声エージェントの中身。
この“声で仕事をするAI”は、すでに現場へ入っている。コンサルティング大手のPwCは、OpenAIのRealtime APIを既存のコールセンター基盤と組み合わせ、用件を理解して実際に処理まで進める音声エージェントを構築した。電話の取り次ぎ(たらい回し)を減らし、肝心な場面の応対を底上げするのが狙いだ。エンタープライズ向けでは、ElevenLabsとIBMが手を組み、業務用AIエージェントに高品質な音声を載せる動きも4月に発表されている。
なぜ「いま、声」なのか
音声AIの市場規模は、2026年時点で約64億ドル。年平均30%超という勢いで膨らみ続けている。背景には、技術的な“ある変化”がある。
かつて差別化の決め手だった応答の速さ(遅延の短さ)は、もはや当たり前になった。主要なサービスはどこも、人の感覚で「待たされた」と感じない1秒未満の応答を実現している。速さで勝負がつかなくなったいま、競争の焦点は次の3つへ移っている——雑音や訛りの混じる現実の音声をどれだけ正確に聞き取れるか、負荷がかかっても道具呼び出しが破綻しないか、そして料金が実際のビジネスで成立するかだ。
ちなみにコストの目安として、OpenAIのリアルタイム音声は1分の対話でおよそ0.3ドル前後(入力・出力合算、キャッシュ前)。安くはないが、人間のオペレーターの人件費と並べたとき、用途次第で十分に現実的な数字になってきている。
編集部の視点
この2つのニュースを並べると、音声AIの“地図”が描き変わったのが見えてくる。
ElevenLabsが攻めるのは声の質感=感情。OpenAIが攻めるのは声の中身=行動(エージェント)。一見ちがう方向に見えて、向かう先は同じだ。声を、人とAIをつなぐ標準の窓口にする——その一点で重なっている。
注意したいのは、ここで本当に難しいのは“技術”ではなく“信頼”だという点だ。スタニシェフスキ氏が言うように、ロボットのような声では人は心を開かない。逆に、自然で感情のこもった声がスラスラ用件をこなすほど、私たちは相手が機械であることを忘れていく。便利さと同じ速さで、「これは誰の声で、何を根拠に話しているのか」を見分ける目が要る時代になる。
個人開発者やブログ運営者にとっては、追い風でもある。かつてプロのナレーターや吹き替えスタジオが必要だった音声コンテンツが、APIひとつで手の届く距離に来た。動画、教材、問い合わせ対応——「文字で作っていたもの」を「声で届ける」選択肢が、いよいよ現実的なコストに乗ってきた。声は、次に個人が手にする大きな武器になる。
要点まとめ
- 音声AIの“自然さ”はほぼ達成され、主戦場は 感情 と エージェント化 へ移った。
- ElevenLabs v4(披露段階)は囁き・歌・感情まで操り、吹き替えD2は元音声から感情ごと翻訳する。
- OpenAI Realtime API は正式版に。GPT-Realtime-2 は割り込み・並行ツール・12.8万トークン文脈で“声で仕事をする”。電話回線にも直接出られる。
- 市場は約64億ドル・年30%超成長。差別化は速さから精度・信頼・コストへ。声は次のインターフェースになる。
出典
- ElevenLabs wants AI to sound human — its next model can whisper, sing and sell(xyz.pl, 2026年6月): https://xyz.pl/poland-unpacked/elevenlabs-wants-ai-to-sound-human-its-next-model-can-whisper-sing-and-sell-1121/
- Introducing gpt-realtime and Realtime API updates for production voice agents(OpenAI): https://openai.com/index/introducing-gpt-realtime/
- Enterprise AI finds its voice: ElevenLabs and IBM bring premium voice to agentic AI(IBM Newsroom, 2026年4月): https://jp.newsroom.ibm.com/2026-04-16-enterprise-ai-finds-its-voice-elevenlabs-and-ibm-bring-premium-voice-capabilities-to-agentic-ai
- PwC’s real-time voice agent powered by OpenAI(PwC): https://www.pwc.com/us/en/technology/alliances/library/open-ai-dcs-launch-engine-brief.html





コメントを残す