要点(30秒で): ChatGPTのようなAIは、いまや「自分のパソコンの中だけ」でも動かせる。ネットにもつながず、課金もされず、データを一切外に出さずに。2026年、Qwen・Llama・Gemma・Mistralといったオープンなモデルが一気に賢くなり、その敷居は驚くほど下がった。この記事では、ローカルLLMとは何か、なぜ使うのか、そして「自分のPCではどれが動くのか」を、実際に毎晩ローカルLLMで記事を下書きしている編集部の目線で、やさしく整理する。
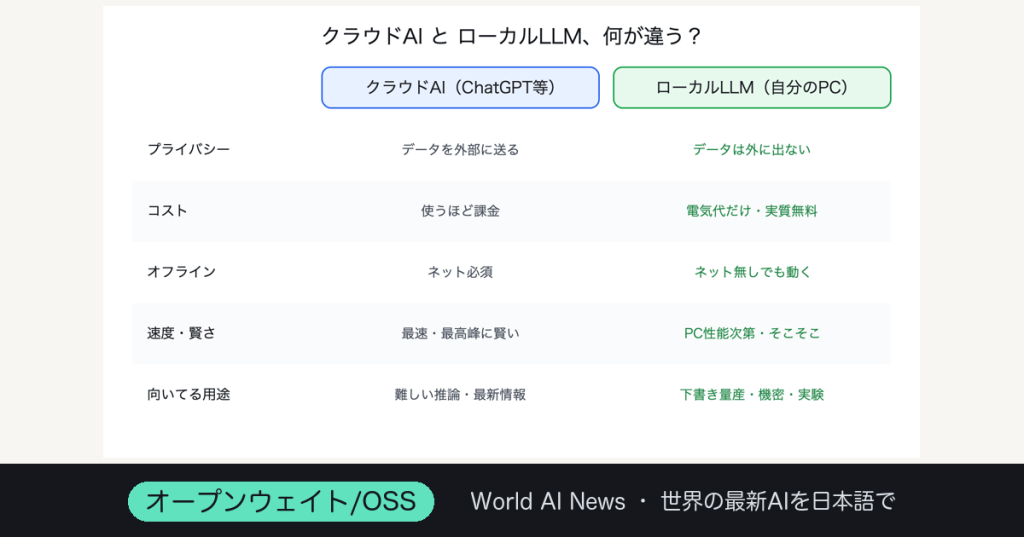
「AIを使う」と言えば、ふつうはChatGPTやClaude、Geminiをブラウザで開くことを指す。便利だけれど、その裏では、あなたの打ち込んだ文章が遠くのデータセンターに送られ、使うたびにお金がかかり、ネットが切れれば何もできない。
でも実は、2026年のいま、まったく別の選択肢が現実的になっている。AIを、自分のパソコンの中だけで動かす——それが「ローカルLLM」だ。
そもそもローカルLLMって何? ── 「自分のPCの中のChatGPT」
ローカルLLMをひとことで言えば、「自分のPCの中で動く、ChatGPTのようなAI」だ。LLM(大規模言語モデル)の本体を自分のマシンにダウンロードして、そこで直接動かす。質問も、文章生成も、ぜんぶ手元で完結する。クラウドのAIと違って、入力した内容はどこにも送られない。
少し前まで、これは一部のマニアか、高価なGPUを積んだ研究者だけのものだった。ところが状況が変わった。オープンに公開される「オープンウェイト」モデルが急速に賢くなり、しかも軽量化が進んで、ふつうのノートパソコン——特にApple SiliconのMac——でも、実用的な速度で動くようになったのだ。
なぜわざわざ自分のPCで動かすのか ── 4つの理由
「クラウドのAIで十分なのに、なぜ手間をかけて自分のPCで?」と思うかもしれない。理由は、大きく4つある。
ひとつ目は、プライバシー。入力したデータが一切外に出ない。社外秘のコード、顧客情報、未公開の原稿、個人的な悩み——クラウドに送るのをためらう内容を、安心してAIに相談できる。
ふたつ目は、コスト。一度モデルを入れてしまえば、あとは何回使っても無料だ。かかるのは電気代だけ。大量の文章を処理させても、APIの請求に怯える必要がない。
みっつ目は、オフラインで動くこと。ネットがなくても、飛行機の中でも、回線が不安定な場所でも、AIが使える。
そしてよっつ目が、一番じわじわ効いてくる——「取り上げられない」ことだ。クラウドのAIは、ある日サービスが終わったり、料金が上がったり、利用制限が厳しくなったりする。でも、自分のPCに入れたモデルは、誰にも止められない。完全に、あなたのものだ。

2026年、ローカルLLMはここまで来た
「とはいえ、自分のPCで動くAIなんて、おもちゃみたいなものでしょ?」——数年前なら、その通りだった。でも2026年の景色は、まるで違う。
いま主役になっているのは、4つの系統だ。アリババのQwen、メタのLlama、グーグルのGemma、そしてフランスのMistral。どれもオープンに公開され、無料で使える。
特に進化が著しいのがQwenで、最新のQwen3.5は、合計1220億パラメータという巨大さながら、一度に動くのはそのごく一部だけ(MoEという賢い仕組み)という設計で、64GBのメモリを積んだMacなら動いてしまう。グーグルのGemma 4は、Apache 2.0という使いやすいライセンスで画像も扱え、実用上の本命とも言われる。軽さで選ぶなら、バランスのいいLlama 3.3 8Bや、速度に定評のあるMistral Small 7Bといった選択肢もある。
数年前まで、「フロンティアモデル(最先端)」と「手元で動くモデル」のあいだには、絶望的な差があった。その差が、いま、目に見えて縮まっている。これは2026年のAIで、もっとも静かで、もっとも大きな地殻変動のひとつだ。
4つのモデル、それぞれの「性格」
同じ「オープンなLLM」でも、4つの系統にはそれぞれ個性がある。選ぶときの参考に、ざっくりした人物像を描いておく。
Qwen(アリババ)は、いまもっとも勢いのある優等生。サイズ展開が幅広く、特にコードや論理的な作業に強い。最新のQwen3.5は、巨大ながら手元で動くMoE設計で、ローカル派の注目株だ。Llama(メタ)は、オープンLLMの草分けにして定番。クセがなく情報も多いので、最初の一台として失敗が少ない。困ったとき、世界中の先人の知恵が見つかりやすいのも安心材料だ。
Gemma(グーグル)は、軽さと賢さのバランスが良く、ライセンスも使いやすい。画像を扱える版もあり、「実用上の本命」と評する声も多い。ふつうのノートPCで、いちばん気持ちよく動く部類だ。Mistral(フランス)は、ヨーロッパ発の俊足。少ないメモリでも返答が速く、「待たされるのが何より嫌」という人と相性がいい。どれも無料で試せる。性格が違うだけで優劣ではないので、気になったものから触ってみるのがいい。
あなたのPCで、どのモデルが動く? ── メモリで決まる
ローカルLLMで一番大事なのは、「自分のPCで、どのサイズのモデルが動くか」を知ることだ。そしてその答えは、ほぼメモリ(RAM)の量で決まる。
ここでMacユーザーに朗報がある。Apple Siliconのマシンは「ユニファイドメモリ」という仕組みで、積んでいるRAMをそのままAIの計算に使える。ふつうのPCだと、AIの計算には主にグラフィックボードの専用メモリ(VRAM)が要るが、Macはその区別がない。つまり、メモリが多いほど、大きく賢いモデルが動く。

ざっくりした目安はこうだ。8GBなら、3〜4Bクラスの小型モデルで、要約や下書きならこなせる。16GBあれば、7〜12Bクラスが動いて、ここが「日常使いの実用ライン」。32GBになると30B級まで狙え、かなり賢く、仕事にも効いてくる。そして64GB以上なら、大型のMoEモデルが動き、フロンティア級に迫る賢さを手元で味わえる。まずは自分のマシンのメモリを確認する。それが、ローカルLLM選びの出発点だ。
「重いモデルが、なぜ普通のPCで動くの?」 ── 量子化のはなし
ひとつ、不思議に思うかもしれない。1220億パラメータなんて巨大なモデルが、どうして家庭用のPCで動くのか。
その種明かしが、量子化(クオンタイズ)という技術だ。モデルの中身は、本来とても細かい数値の集まりでできている。その数値を、賢さをほとんど損なわない範囲で「ざっくり」に丸めると、サイズが数分の一に縮む。フルサイズでは到底載らないモデルが、量子化版なら手元のメモリに収まる、というわけだ。
ありがたいことに、この調整も、さきほど触れるOllamaのようなツールが自動でやってくれる。利用者は難しいことを考えず、「自分のPCで動くサイズ」を選ぶだけでいい。
始め方は、拍子抜けするほど簡単(Ollama)
「難しそう」と身構えるかもしれないが、いまは驚くほど簡単になっている。鍵を握るのが、Ollamaという無料ツールだ。
Ollamaを入れれば、モデルのダウンロードも、サイズ調整(量子化)も、実行も、たった1つのコマンドで済む。たとえばターミナルで ollama run gemma4:12b と打てば、それだけでGoogleのGemmaが自分のPCで起動し、対話が始まる。Qwenを試したければ ollama run qwen3.5。本当に、これだけだ。
昔のように、複雑な環境構築や、難しい設定ファイルと格闘する必要はもうない。最初の一歩は、思っているよりずっと軽い。
最初の10分でやること ── インストールから初対話まで
理屈はこのくらいにして、実際の流れを書いておく。本当に10分あれば、最初の対話までたどり着ける。
まず、Ollamaの公式サイトから、自分のOS向けのアプリをダウンロードしてインストールする。次に、ターミナル(Macなら「ターミナル」アプリ)を開く。そして、自分のメモリに合ったモデルを一行打つだけ。16GBなら、たとえば ollama run gemma4:12b。
初回はモデルのダウンロードに数分かかるが、それが終われば、もうそこはAIとの対話画面だ。試しに「自己紹介して」と打ってみる。ネットを切っていても、ちゃんと返事が返ってくる——その瞬間、「自分のPCの中でAIが動いている」ことを、はっきり実感できるはずだ。
結局、どれを入れればいい? ── 目的別のおすすめ
モデルがたくさんあって迷う、という人のために、目的別の入り口を挙げておく。
「まず雰囲気を試したい」なら、軽くて賢いGemmaの小型版から。ollama run gemma4:12b あたりが、16GBのマシンでも軽快に動いて、最初の感動を味わいやすい。「日常の相棒にしたい」なら、7〜12Bクラスを常駐させる。Mistral Smallは返答が速く、待たされるストレスが少ない。Llamaはクセがなく、何でも無難にこなす。
「仕事でしっかり使いたい」なら、メモリを積んで30B級へ。Qwen3の32BやGemma 4の26Bは、込み入った文章やコードにも、かなり食らいついてくる。そして「最強を手元に置きたい」なら、64GB以上のマシンで大型MoEへ。Qwen3.5のような巨大モデルが、自分の机の上で動く——その体験には、ちょっとした感動がある。迷ったら、まず小さく始めて、物足りなくなったら一段上げる。これが遠回りに見えて、いちばん確実だ。
ローカルLLMで、実際に何ができる?
入れてみたものの、何に使えばいいのか——という人のために、相性のいい用途を挙げておく。
まず、文章まわり。下書き、要約、言い換え、翻訳。大量のメモや議事録を、人に見せる前にざっと整える作業は、ローカルでも十分こなせる。次に、コードの補助。簡単な関数を書かせたり、エラーの意味を聞いたり。社外に出せない社内コードを扱うときほど、ローカルの安心感が効く。
そして、誰にも見られたくない壁打ち相手として。悩みごとの整理、企画のたたき台、言いにくいことの下書き——クラウドに残したくない類の相談を、気兼ねなく投げられる。共通するのは「大量・機密・オフライン」。この3つのどれかに当てはまるなら、ローカルLLMはぴったりはまる。
つまずきやすいポイント Q&A
最後に、始めた人がよくぶつかる疑問に、手短に答えておく。
遅いんだけど? メモリに対してモデルが大きすぎる可能性が高い。一段小さいモデルに変えると、ぐっと軽くなる。思ったより賢くない? ローカルモデルは万能ではない。難しい仕事はクラウドに回し、ローカルは得意な作業に絞ると、評価が変わる。仕事で使っていい? モデルごとにライセンスが違う。商用利用しやすいものも多いが、必ず各モデルの規約を確認したい。日本語は大丈夫? 最近のモデルは日本語もかなり自然だ。ただ英語よりは少し不安定なことがあるので、大事な文章は人間が見直すのが安全だ。
正直な話:ローカルLLMの「弱点」も知っておく
ここまで良いことを並べてきたが、フェアに弱点も書いておきたい。夢を見すぎて始めると、がっかりするからだ。
まず、賢さでは、やはり最先端のクラウドAIにはかなわない。GPT・Claude・Geminiといったフロンティアモデルは、桁違いのサイズと計算資源で動いている。手元のモデルは年々それに迫ってはいるが、本当に難しい推論や、込み入った長文の処理では、まだクラウドに分がある。
次に、速度。高性能なPCでなければ、返答はクラウドより遅く感じる。編集部の環境でも、文章がスルスル出てくるというより、一文字ずつ着実に紡がれていく感覚に近い。そして、最新情報を知らないこと。ローカルモデルは学習した時点までの知識しか持たず、そのままではネット検索もしない。「今日のニュース」を聞いても答えられない。
だから、万能の道具ではない。クラウドAIを置き換えるものではなく、用途で使い分ける相棒、と考えるのが正解だ。
クラウドとローカル、こう使い分ける
では実際、クラウドAIとローカルLLMを、どう使い分ければいいのか。編集部なりの、現実的なレシピを書いておく。
ローカルに任せるのは、「量が多い」「外に出せない」「ネットがない」作業だ。大量の下書き、機密を含む相談、移動中の作業。ここはコストも気にせず、安心して回せる。一方、クラウドに頼むのは、「本当に賢さが要る」「最新情報が要る」場面。込み入った推論、最終仕上げ、いままさに起きているニュースのリサーチ。ここは惜しまず最先端のモデルを使う。
この線引きさえ持っておけば、両者は競合しない。むしろ、互いの弱点をきれいに埋め合う。安い力仕事はローカルに、高い知恵はクラウドに。シンプルだが、これがいちばん、財布にも精神にも優しい付き合い方だ。
編集部の実体験:「夜の記事工場」の話
最後に、編集部の正直な使い方を打ち明けたい。実は、このメディアの裏側でも、ローカルLLMが働いている。
夜、人間が眠っているあいだに、64GBのMacの中でローカルモデルが静かに動き、記事の下書きやネタの整理を進めておく——勝手に「夜の記事工場」と呼んでいる仕組みだ。クラウドのAPIだと、これだけ大量に回せば料金が気になる。でもローカルなら、電気代だけで、何時間でも、何十本でも回せる。気兼ねがまるでない。
もちろん、夜の工場が吐き出すのは、あくまで「粗い下書き」だ。そこから先、本当に読ませる文章にする仕上げは、より賢いAIと人間の手が引き受ける。重くて単純な作業はローカルに任せ、繊細で重要な判断は別の場所で。この役割分担が、地味だが、よく効く。
派手ではない。でも、「自分の手元に、いつでも使える、誰にも止められないAIがある」という安心感は、一度知ると、もう手放せない。
オープンウェイトという「思想」 ── なぜ各社は無料で公開するのか
ここで、ひとつ素朴な疑問が浮かぶかもしれない。Qwenも、Llamaも、Gemmaも、開発には莫大なお金がかかっているはずだ。なぜ各社は、それを無料で公開するのか。
理由はいくつもあるが、根っこにあるのは「囲い込みへの対抗」だ。一部の巨大企業だけがAIを握り、利用料も使い方も向こうの胸先三寸——そんな未来に抗うために、あえてモデルを世界へ開放する。開放されたモデルの上には、世界中の開発者が改良を重ね、エコシステムが育つ。閉じて独占するより、開いて主導権を分散させたほうが強い、という賭けでもある。
この「閉じたAI 対 開いたAI」という対立は、2026年のAIをめぐる最大のテーマのひとつだ(編集部でも別記事で深掘りしている → 「閉じたAIはもう続かない」LeCunが描く世界分散AIの設計図)。そして、ローカルLLMを自分のPCで動かすという行為は、その大きな流れに、個人として一票を投じることでもある。難しい話に聞こえるかもしれない。でも、やっていることは「自分のMacにAIを一つ入れる」だけ。その小さな一歩が、実は時代の本流につながっている。
🐦⬛ 編集部の視点
ローカルLLMの一番の価値は、たぶん「賢さ」ではない。主導権だ。
いまAIの世界では、巨大企業が電力と半導体を奪い合っている。その先に待っているのは、ほぼ確実に、利用料金の値上げや、無料枠の縮小だ。クラウドのAIに全部を預けていると、その波をまともに受ける。けれど、自分のPCの中にひとつ、そこそこ賢いモデルを持っておけば、外で何が起きても、AIが完全に手から離れることはない。
だから編集部は、こう考えている。最先端の賢さは、クラウドから借りればいい。でも、土台になる一台は、自分の手元に置いておく。この二刀流が、これからのAIとの、いちばん健全で、いちばん強い付き合い方なんじゃないか、と。
あなたのMacにも、今夜、小さなAIを一つ住まわせてみてはどうだろう。きっと、世界の見え方が少し変わる。





コメントを残す